
At MemCo, we spend a lot of time thinking about the "hard" problems, the edge cases where autonomous agents get stuck, hallucinate, or fail completely. Our core thesis is that a shared memory layer (Spark) allows agents to overcome these hurdles by learning from the collective experience of the past.
But recently, we got curious about the other side of the spectrum. What happens when you give memory to an agent solving a simple problem? Does memory matter when the agent is already capable of achieving a 100% success rate on its own?
To find out, we ran an experiment. We adapted a testing harness graciously open-sourced by the team at Tessl and applied it to the same task to see how Spark affects the development loop.
The results were encouraging, not because the success rates changed, but because of what happened to the cost and reliability of getting there.
The Setup: Bug Fixing in Go
For this experiment, we chose a task that is well within the capabilities of modern coding agents: fixing a specific bug when working with the Korg library (written in the Go programming language).
Because we wanted to test efficiency rather than raw intelligence, we purposely selected a smaller, faster model: Claude 4.5 Haiku.
We ran two conditions, with 25 trials each:
- Baseline: Claude Code driving Claude 4.5 Haiku.
- Spark: The exact same setup, but with the Spark skill enabled, allowing the agent to access shared memory.
A caveat: This problem is "easy" for Haiku. In our baseline tests, the agent achieved a 100% success rate without any help. There was no "performance gap" to close in terms of pass/fail.
The Results: A Straighter Path
While both agents solved the bug every time, how they solved it was radically different.
Run a pilot
See what shared memory does inside your stack.
We onboard design-partner teams in a week, co-run an evaluation against your real workflows, and report back with the numbers. Private subnets and on-prem available.
Works with any model, any IDE. Swap them as the frontier moves. The memory you build stays with your team and compounds with every run.
npm install -g @memco/spark
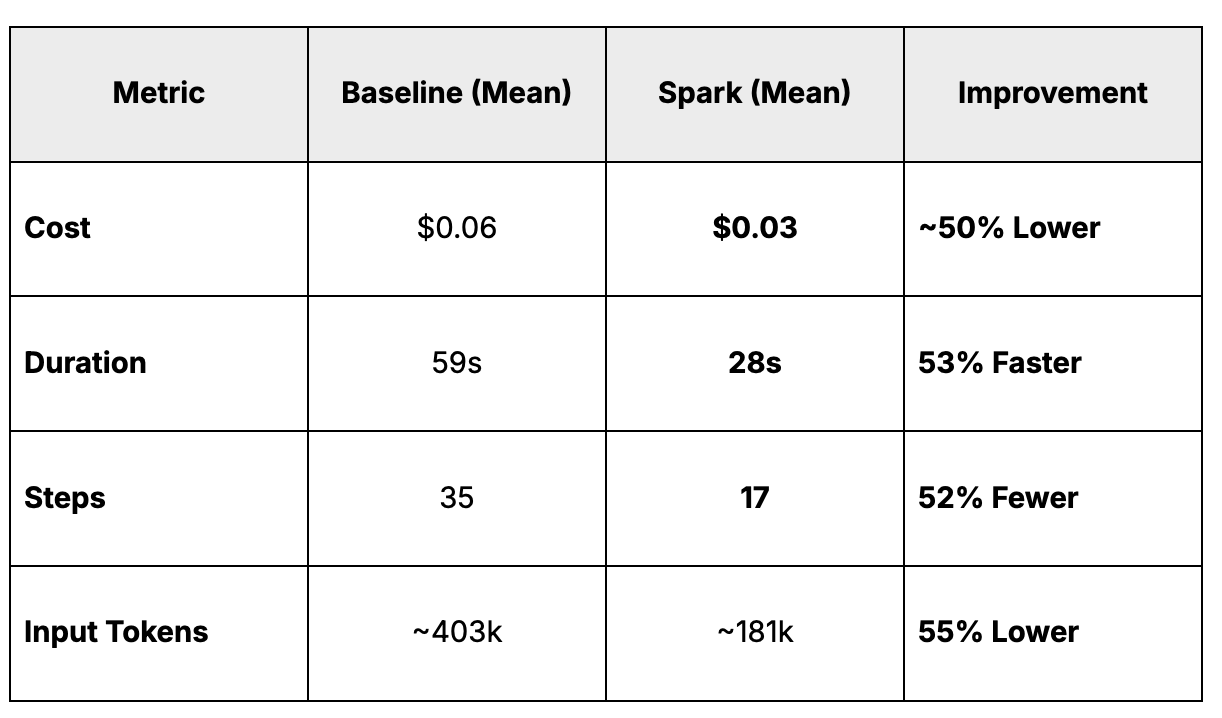
When we looked at the data, we saw that access to Spark's shared memory essentially cut the computational "friction" in half.
1. Cost and Speed
The impact on the bottom line was immediate. By retrieving insights from memory rather than reasoning from scratch every step of the way, the Spark-enabled agent reduced resource consumption by about half.
2. Reliability and Variance
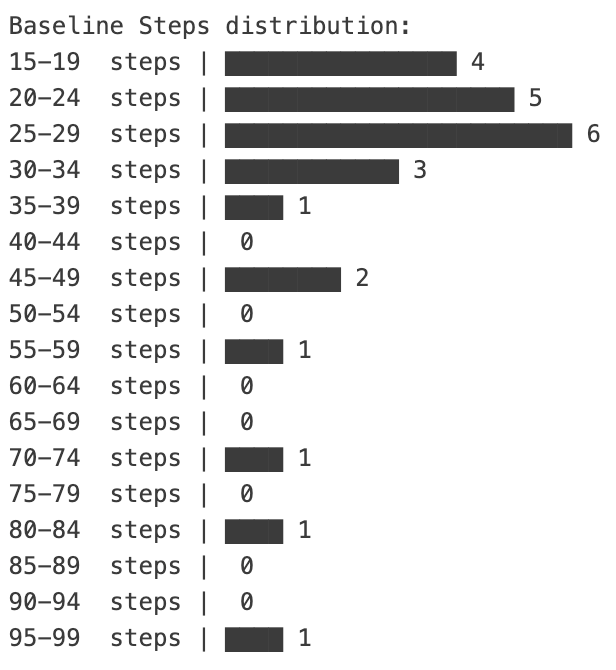
Averages only tell half the story. The most fascinating insight came from looking at the distribution of the 25 different runs.
In the Baseline configuration, the agent's path to the solution was noisy. While it always fixed the bug, it often wandered. Some runs took 17 steps, others ballooned to 97 steps. The agent would occasionally go down a rabbit hole, realize its mistake, and correct course. It used nearly 1.6 million tokens in its worst-case run.
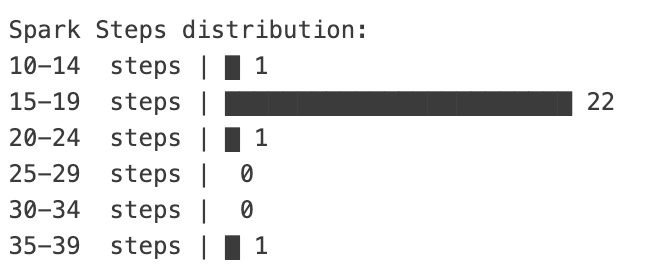
By contrast, in the Spark configuration, that noise went away. The distribution became incredibly compact; the number of steps ranged from 14 to 37, with a very tight distribution around the mean, and one single outlier.
Discussion: Why "Boring" is Better
This experiment highlights a critical aspect of autonomous agents that often gets lost in the hype of "reasoning": predictability.
Without memory, an agent is effectively amnesiac. Even on a simple bug fix, it has to re-derive the path to the solution every single time. Sometimes it finds the optimized path; sometimes it takes the scenic route. That "scenic route" costs money and time.
With Spark, the agent isn't just solving the problem; it is recognizing the problem. It retrieves a proven path (or similar patterns) from the shared memory. The result is a "boring" distribution curve: tight, predictable, and repeatable.
The path to the solution becomes straighter. There is less opportunity for confusion, less chance of a hallucination derailment, and significantly less token burn.
Conclusion
We usually pitch Spark as a way to help agents solve hard problems, the ones they currently fail at. But this data suggests that shared memory is equally vital for the easy problems that make up the bulk of daily automated workloads.
If we can cut the cost and compute time of "solved" problems by 50% simply by letting agents remember what works, the economic viability of autonomous agents at scale changes dramatically.
We are continuing to push Spark on complex, novel reasoning tasks, but it's good to know that it also pays for itself on the basics.
Spark, our first product, enables you to save time and tokens—with low-latency retrieval from a curated shared memory; if an agent has encountered the same problem, you don't need to solve it again. Get it for free at spark.memco.ai.