
Harrison Chase, founder of LangChain, recently shared a useful taxonomy for thinking about continual learning in AI agents: systems can improve at three layers - the model, the harness, and the context.
That framing matters because it breaks people out of the default assumption that "continual learning" means retraining weights.
For the last two years, most conversations about agent improvement have collapsed into model talk. Better base models. Better post-training. Better fine-tuning. Better reinforcement learning. All of that matters. But in practice, most enterprise systems are not failing because the underlying model is incapable. They are failing because the system around the model cannot retain, refine, and reuse what the organization has already learned.
That is a different problem.
And in enterprise AI, it is increasingly the important one.
The model layer will keep getting better. The harness layer will keep getting better. But the hardest and most valuable work sits inside what Harrison calls the context layer.
I would describe that layer more precisely as memory.
That distinction is not semantic. It changes what you build.
Model learning is real - but it is not the practical bottleneck
When most people hear "continual learning," they still think about updating the model itself.
That is the classic research framing: how do you adapt weights over time without catastrophic forgetting? How do you train on new data without breaking old capabilities? How do you personalize behavior at scale without fragmenting the model?
Those are real problems. Frontier labs will keep pushing on them. Some of the largest long-term wins in AI will eventually come from models that genuinely improve through ongoing experience.
But that is not where most enterprises will get their first 10x improvement.
Most companies do not need an agent that becomes generally smarter every day. They need an agent that becomes locally smarter inside the company.
They need systems that learn things like:
- which CRM field is actually canonical after a messy migration
- how finance defines revenue this quarter versus last quarter
- which customers require a specific approval path before discounts are offered
- which engineering runbook is stale even though it still ranks first in search
- which legal clause always creates friction in a certain region
- which workflows are team-specific, and which can be shared more broadly
That kind of knowledge changes quickly. It is highly contextual. It is often permission-sensitive. And in many cases it should not be baked permanently into model weights at all.
It needs to be visible. Editable. Reversible. Scoped. Auditable.
Weight updates are too global and too blunt for most of this work.
Harnesses matter - but harnesses alone do not compound
The second layer in Harrison's taxonomy is the harness: the code and scaffolding around the model that makes it useful.
This includes orchestration, tools, prompts, error handling, planning loops, search behavior, execution logic, verification, trace capture, and the rest of the environment the model operates inside.
Harness engineering is very real leverage. The difference between a raw model and a useful agent is usually the environment around it.
That is why the category has exploded. Better coding agents, better planning loops, better tool calling, better subagents, better guardrails, better eval-driven iteration. Everyone serious in agent infrastructure is improving the harness now, and they should be.
But harnesses are also starting to crowd together.
Over time, many harness capabilities will become table stakes. Good search. Good tool integration. Good trace collection. Good planning. Good runtime state management. Those things matter, but they are not enough to explain where enduring enterprise advantage will live.
The more interesting question is what happens after the harness finishes a piece of work.
What survives from that run? What gets promoted into reusable organizational knowledge? What gets discarded? What gets scoped to a user, a team, or an entire company? What gets revised when reality changes?
That is not mainly a harness question.
That is a memory question.
Context is too broad a word
One reason this category still feels fuzzy is that "context" gets used to mean too many different things.
A static instruction file is context. A task-specific prompt is context. A skill file is context. A user preference is context. A prior trace can become context. A policy document can become context. Team conventions can become context.
But these things are not equivalent.
A cleaner distinction is this:
Context is what the model sees right now. Memory is the system that decides what from the past deserves to show up in that context.
That sounds like a small wording change. It is not.
Run a pilot
See what shared memory does inside your stack.
We onboard design-partner teams in a week, co-run an evaluation against your real workflows, and report back with the numbers. Private subnets and on-prem available.
Works with any model, any IDE. Swap them as the frontier moves. The memory you build stays with your team and compounds with every run.
npm install -g @memco/spark
If you think in terms of context alone, the problem looks like prompt assembly. Gather relevant information and place it into the window.
If you think in terms of memory, the problem gets much harder, and much more interesting:
- What should survive from prior runs?
- What should decay?
- What is stale?
- What conflicts with something newer?
- What belongs to one user versus an entire org?
- What has strong provenance versus weak inference?
- What actually helped when it was injected back into a workflow?
This is the difference between a retrieval system and a learning system.
Without memory, "continual learning at the context layer" often becomes a nicer phrase for prompt accumulation.
And prompt accumulation does not compound. It clutters.
Enterprise memory is not just storage. It is judgment.
This is where the real product work begins.
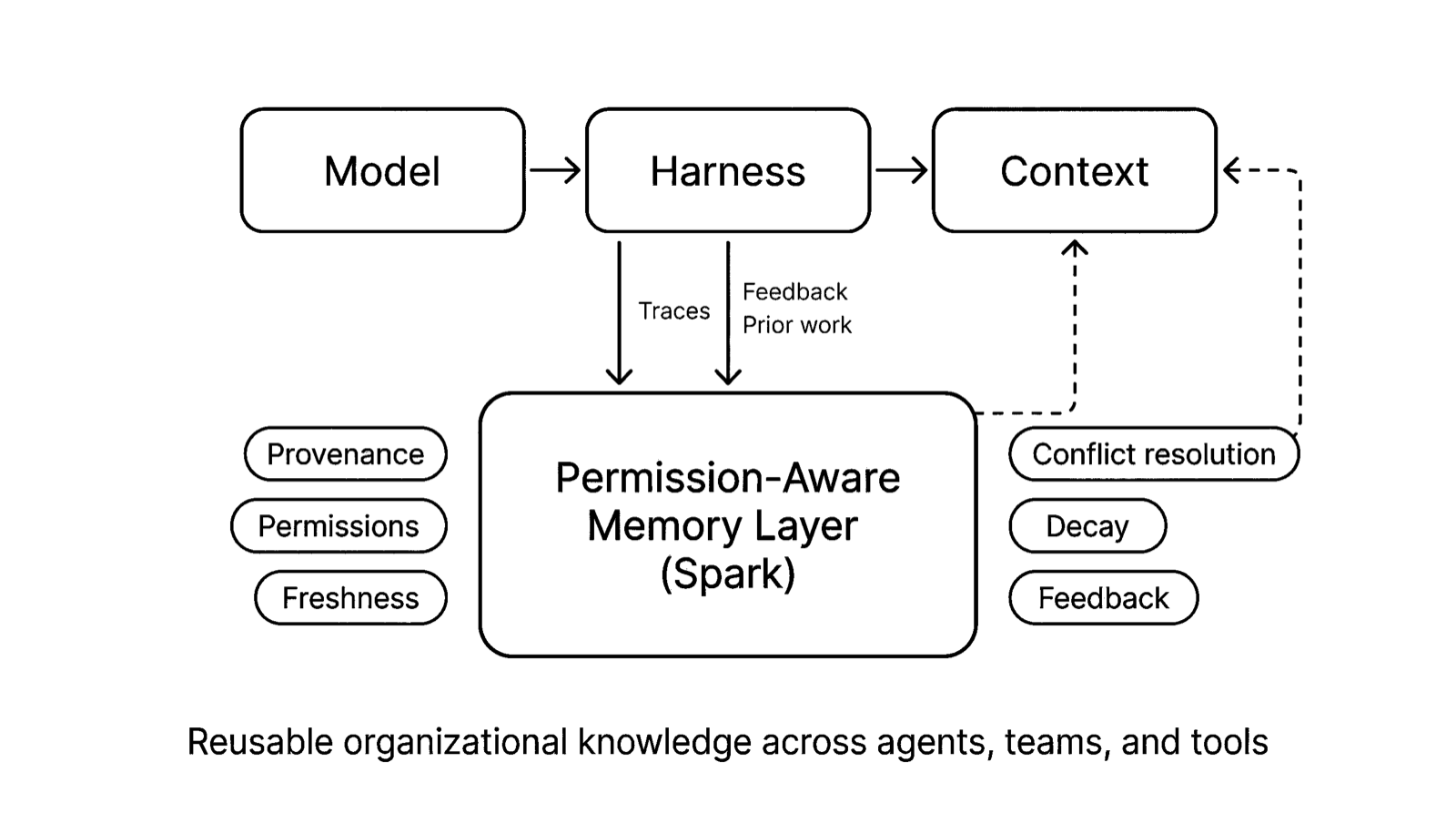
A serious memory layer for enterprise AI is not just a place to dump logs, traces, and notes. It has to make decisions.
It needs provenance: Where did a piece of knowledge come from? A successful trace? A human correction? A support escalation? A doc someone forgot to update? A guessed summary produced by another model?
It needs permissions: Who should be allowed to use this? One agent? One team? The whole company? A specific workflow with hard boundaries?
It needs freshness: Is this still true? Was it true three weeks ago but obsolete after the reorg, migration, or policy update?
It needs conflict resolution: What happens when two traces imply different rules? Which one wins? Do we merge them? Rank them? Flag them for review?
It needs decay: What should fade when it stops being reinforced? Enterprise knowledge without forgetting becomes sludge.
It needs feedback: Did this memory actually improve outcomes? Was it ignored? Did it create mistakes? Should it become stronger, weaker, or disappear?
These are not edge cases. They are the system.
Anyone can say agents need memory. The hard part is building memory that an enterprise can trust.
Traces are the raw material - not the finished product
One of the strongest points in Harrison's post is that traces are the core.
That is exactly right.
If you want agents to improve over time, traces are the raw material. They show what the system saw, what it tried, what worked, what failed, what tools were used, where the loop broke, and how a result was produced.
But traces alone are not the product.
A company does not create value simply by collecting 100,000 agent runs. It creates value when those runs are transformed into reusable knowledge.
That requires a loop more like this:
traces -> extraction -> consolidation -> permissioning -> retrieval -> feedback
Imagine a support agent handling hundreds of customer issues. Over time, the system may discover that a particular billing failure should route differently for enterprise customers on a certain contract structure, or that an integration bug has a reliable workaround until a patch ships.
Those are not just logs. They are candidate memories.
Some belong to a single account. Some belong to the support team. Some should become company-wide knowledge. Some should expire automatically when the patch lands.
The value is not in storing all of it forever. The value is in deciding what should persist, in what form, and for whom.
That is where enterprise learning really happens.
The next moat in enterprise AI
As models improve and harnesses proliferate, the strategic center of gravity in enterprise AI will shift toward the layer that makes those systems compound.
Not away from models. Not away from harnesses. But toward the system that captures what the organization has learned and feeds the right parts of it back into future work.
The winning enterprise AI systems will not just answer the next question well. They will get better at operating inside a specific organization over time. They will retain useful lessons, discard bad ones, respect boundaries, and make institutional knowledge operational across users, teams, and tools.
That is how local intelligence compounds.
At Memco, this is how we think about Spark.
Not as a replacement for models. Not as just another harness. But as a permission-aware memory layer that turns traces, feedback, and prior work into reusable organizational knowledge across agents, users, and teams.
The point is not to give companies more prompt context. The point is to help enterprise AI remember the right things.
Because without that, every session starts over. Every workflow relearns the same lesson. Every team rebuilds the same local knowledge. And every promising agent system eventually hits the same wall: it can act, but it cannot compound.
That is the layer we believe matters most. And it is the one we are building.