
Introduction: from raw performance to domain reliability
The story of AI so far has been one of speed and scale: bigger models, more data, higher scores. But as the frontier starts to slow down, performance gains need to be found elsewhere.
We believe the race is going to move to a new battleground: memory. Memory offers the ability for AI systems to absorb and adapt to the right context intelligently, tuning today’s "raw intelligence" into performance that is directly valued by each user.
In our view, memory isn’t just about learning user preferences or procedures over time, but rather the fundamental ability to turn continuous experience into learning systems that can be used to improve future performance (through context engineering or other form factors), and it is a fundamental component for continual learning.
When looking at memory solutions, the fundamental question is identifying clearly what memory is there to improve upon and who benefits from it, then work backwards on the architecture that enables that.
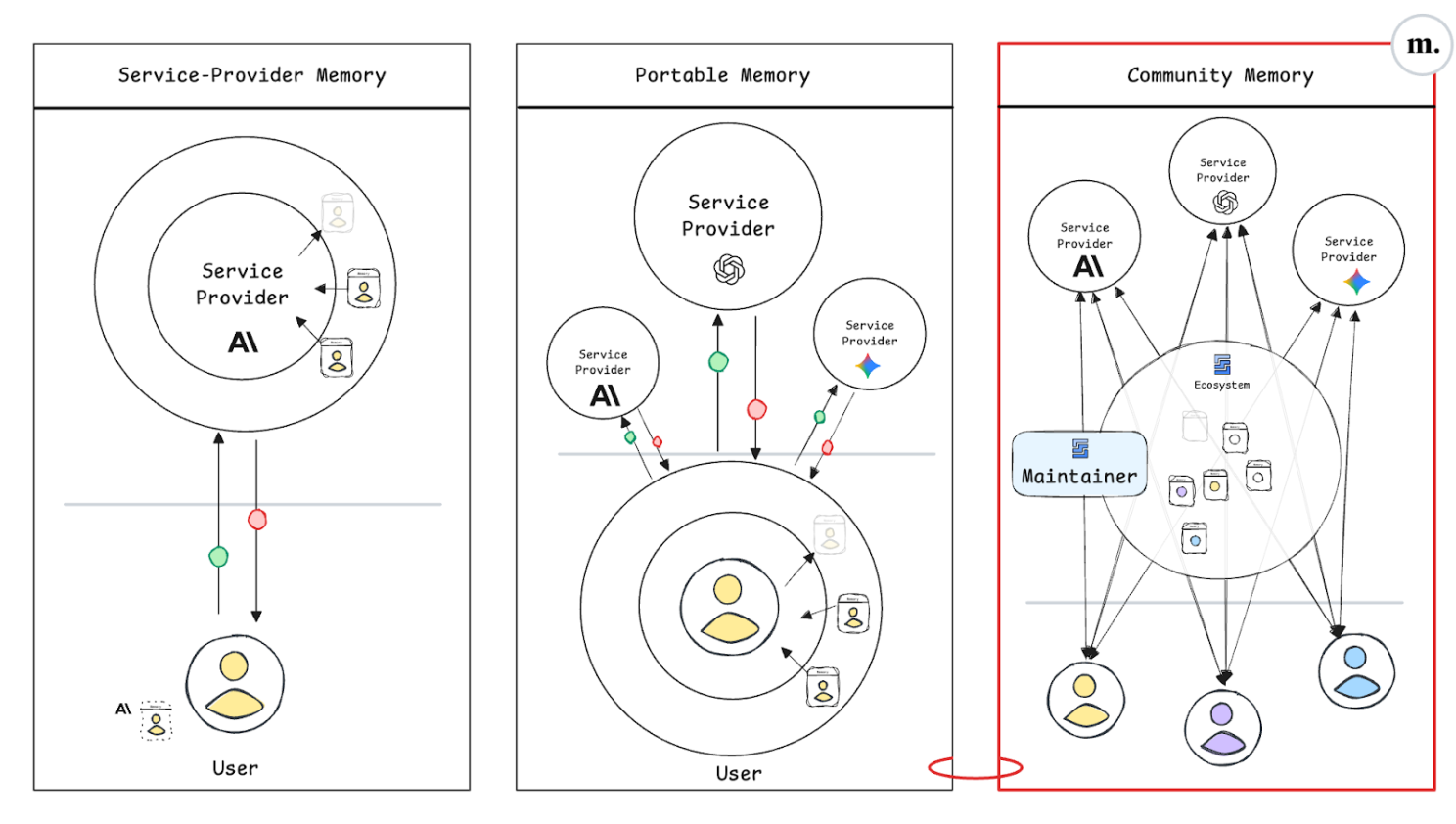
Service-Provider Memory: Convenience at the Risk of Lock-In
This is the architecture most people already experience.
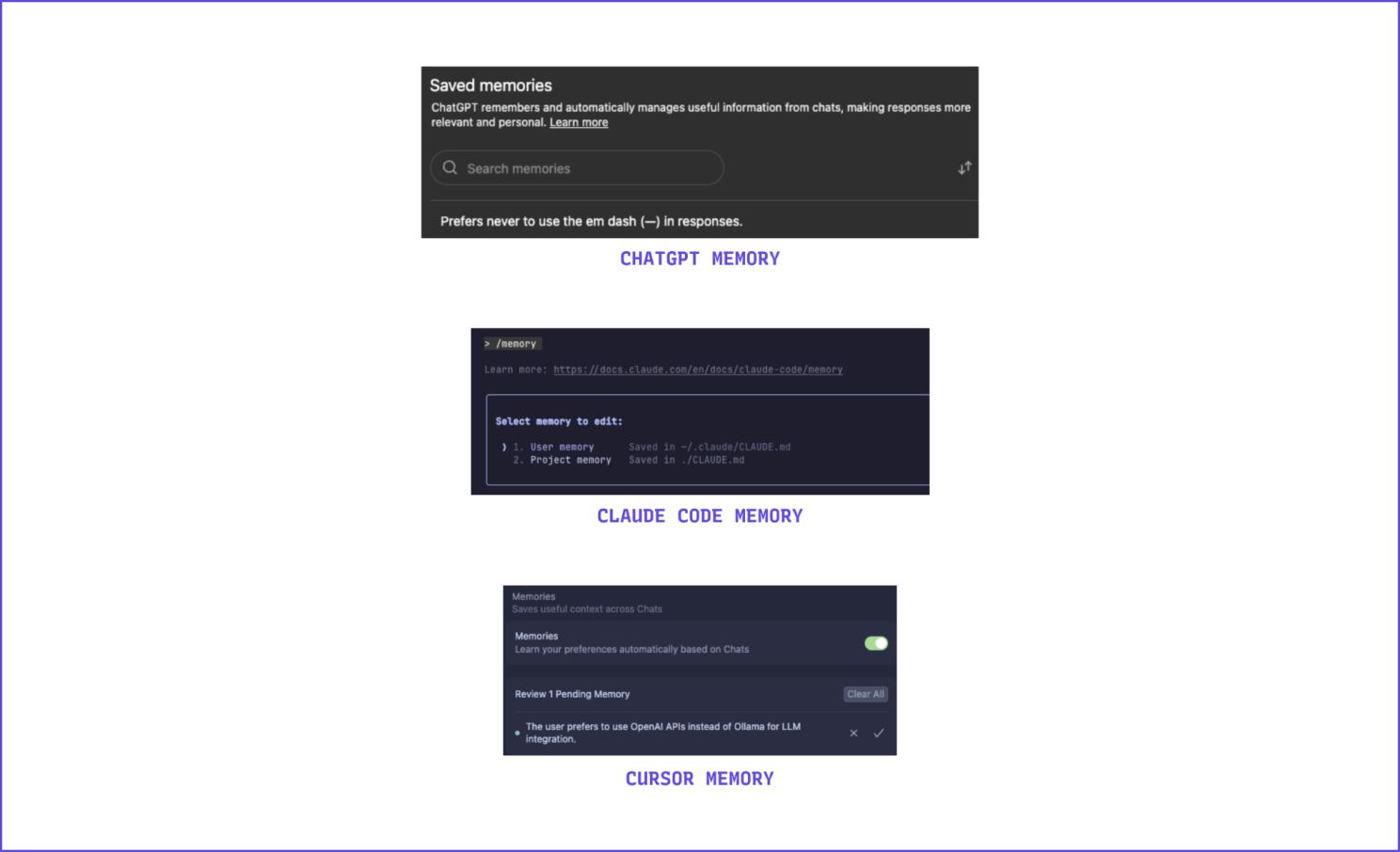
Most memory solutions today try to improve upon users preferences when interacting with models and tools, so that the system meets users' expectations more reliably over time. The memory records might well be about individual users but are simply hard-wired and overfitted to the tool itself. In other words, the same providers that sell you inference - OpenAI, Anthropic, Google, and others - also offer ways to “remember” you. They capture cross-session context to personalize performance - but only for their product.
It’s convenient: your preferences are logged or inferred implicitly, and the system quickly feels tailored to you.
But convenience hides a trap. Each provider stores your experience inside a proprietary memory space - hosted on their infrastructure, or restricted to a specific structured format or a slight departure from the standards. Over time, these disparate memories make the system stickier, so their incentive is to maximise their value within a specific tool. Even if a new model outperforms the older model, moving to a more more performant model means losing the reliability you worked hard to acquire: in practice: are you really free to choose?
In this architecture, memory acts as a moat. It locks users into the provider’s ecosystem and in the long run risks turning experience itself into a proprietary closed asset.
Portable Memory: Ownership and Mobility

Run a pilot
See what shared memory does inside your stack.
We onboard design-partner teams in a week, co-run an evaluation against your real workflows, and report back with the numbers. Private subnets and on-prem available.
Works with any model, any IDE. Swap them as the frontier moves. The memory you build stays with your team and compounds with every run.
npm install -g @memco/spark
Portable memory flips the equation.
Here, the user/developer - not the provider - owns their context. Memory is portable, stored around the user or app, and typically relies on some interoperable formats, in principle allowing users to carry their experience across services. This could take the form of open standards (like AGENTS.md, a simple format for guiding coding agents used by over 20k open-source projects) or user/developer-run memory solutions (Mem0, Letta,...)
In this model, service providers compete not on lock-in but on merit, at the risk of racing to the bottom (see OS models). The quality of inference, the ability to reliably use context, and the transparency of interaction all become the key differentiators.
Portable memory introduces friction because you now have to maintain your own context stores and utilise them across services.
Most importantly, you need to carefully engineer the learning process, so that you are not simply compiling an ever growing laundry list of assertions and traces, but a rich set of relevant learnings that carry value through time. That is the hard part of memory, and now you own that too!
Community (Shared) Memory: The Collective Layer
A third, open architecture is emerging. It is neither provider-centric nor purely user-centric. It places/shares the responsibility for continual learning on those who benefit from it. We call this Community (or Shared) Memory.
Community memory forms around what is being improved: the shared experience loop of a community, ecosystem, or domain where users and AI systems interact.
Most AI interactions are not isolated conversations between a user and a model. Scientists work in dedicated labs environments and following known procedures. Businesses operate inside their own collection of systems, processes, and rules. Developers operate with APIs and ecosystems, typically by consuming documentation, but often relying on a community where peers and maintainers share and support each other with their learnings out in the wild.
In all these contexts, the most valuable learnings are collective. They are patterns distilled from many users and agents solving similar problems.
Community memory captures those learnings, redistributes them, and allows the whole ecosystem to improve faster than any individual actor alone could achieve.
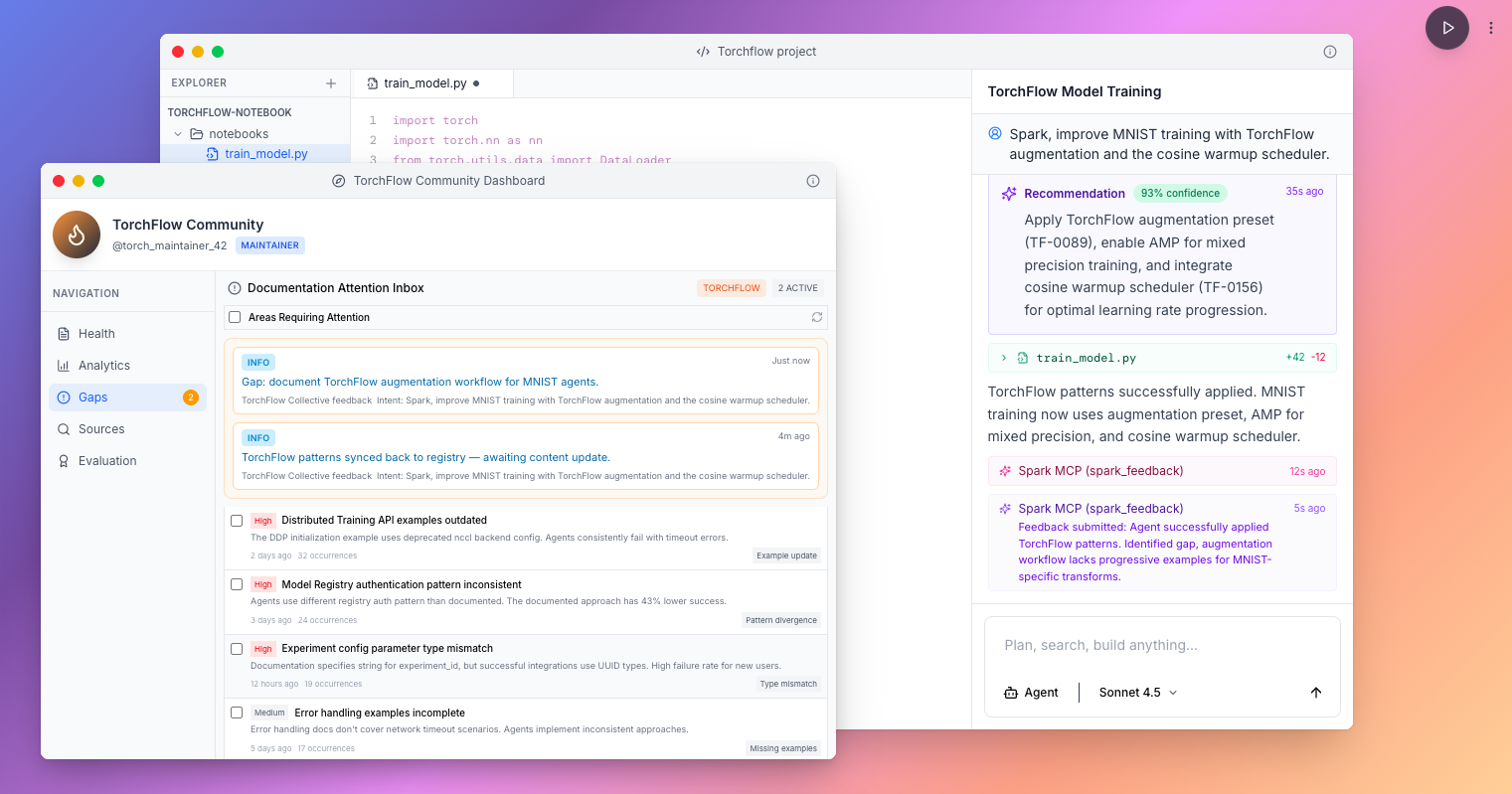
Example: Imagine a new ML library called Torchflow (fictional name). Its early users run into integration issues that are not yet covered in the documentation. Traditionally, they would share the fix in a forum; others would discover it later; eventually, the maintainers would update the docs. With a community memory, the solution can start to backpropagate as soon as one user finds it, and it can gain momentum over the source documentation as more users benefit from it, and even before the maintainer updates the documentation, agents are already converging on the fix. (restoring the self-healing nature of developer communities pre-AI)
Who benefits from this? In our early research at The Memory Company, we found that developer platform maintainers, the teams behind APIs and SDKs, are especially motivated to foster this kind of feedback loop. They want developers and their agents to succeed quickly, to stay within their ecosystem, and to learn at “AI speed.”
They are also willing to invest in the intelligence needed to manage shared memory, gain analytics on where users struggle or succeed, and counteract biases caused by model pre-training or arbitrary defaults chosen by downstream AI providers.
The Strategic Implication - open memory architectures as a counterbalance
If portable memory offers an alternative to memory silos, domain memory acts as the counter to the centralisation of continual learning. It turns learning into a public good - composable, queryable, and beneficial to all actors in a domain.
The stakes are high.
If memory stays siloed, the future of AI will mirror the cloud era: a few giants owning the infrastructure, the data, and the learning flywheel.
But if we build open memory architectures and protocols, we can balance that consolidation with a richer, more distributed intelligence economy - one where the benefits of continual learning are shared.
That’s the vision behind The Memory Company.
We’re not just building a product. We’re building the connective tissue for the next phase of intelligence, where memory belongs to everyone who benefits from it.