Your Team Knows More Than Anyone On It
Most AI memory tools give back what you put in. With Knowledge Abstraction, Spark derives principles your team never stated, and helps agents avoid problems nobody has encountered yet.
Listen to this article
Keeps playing as you browse the site.
At Memco, we have been building Spark, a shared memory layer for AI coding agents. We recently shipped something that goes beyond storage and retrieval, a capability we call Knowledge Abstraction, where the memory itself derives new knowledge that no contributor ever stated.
This post is about what that means in practice, and why it matters more than it might sound.
The AI tooling market has no shortage of memory solutions. Over the past year, "memory" has become a standard feature: markdown files that capture agent preferences, databases that store past interactions, context windows stuffed with project conventions. The approaches vary in sophistication, but the ceiling is the same. The knowledge that comes out of these systems is always a subset of what went in. They are filing cabinets: some tidier than others, but filing cabinets nonetheless.
The Filing Cabinet Problem
Consider a typical scenario. Your team is integrating with a legacy internal API, let's call it PaymentService. The original team that built it is long gone. The documentation is sparse. The API has a habit that makes it particularly dangerous to work with: when it receives input it doesn't like, it accepts it but silently does nothing.
Alice is building a checkout integration. Her agent writes clean, reasonable code. In staging, transactions silently fail: the API returns 200 OK, but no payment is processed. Alice can't determine the cause from the API's external behaviour, the response gives no indication that anything went wrong. She digs into the PaymentService source code and discovers the problem: the API only accepts uppercase currency codes. Her agent had been sending usd instead of USD. She tells her agent, the agent fixes the code and, because the team uses Spark, the agent stores the insight in shared memory.
A few days later, Bob starts building a refund endpoint against the same API. His agent queries Spark before writing code, picks up Alice's insight, and normalises currency codes from the start. Good. But some refunds still fail silently. Bob's agent now has a useful prior: this API has undocumented constraints. It compares passing and failing payloads, isolates the pattern, and discovers that PaymentService truncates description fields longer than 64 characters, and then discards the entire request when it does. The agent stores this second insight into Spark and sends positive feedback on Alice's original finding.
At this point, a conventional memory system has two useful entries. The next engineer who integrates with PaymentService and happens to search for "currency code" or "description length" will find them. The system has done its job as a filing cabinet. The knowledge that comes out is the knowledge that went in.
From Fixes to Principles
But there is a pattern in these two insights that neither Alice nor Bob articulated. Both describe the same underlying behaviour: PaymentService enforces undocumented input constraints and fails silently when they are violated. The specific constraints differ (one is about currency format, the other about field length) but the class of problem is the same.
A senior engineer who had seen both of these incidents would internalise the general lesson: any input to this API might have undocumented constraints, and every call should be verified because the API will not tell you when something goes wrong. That generalisation is one of the most valuable things experience produces. It is the difference between knowing some fixes and understanding the system.
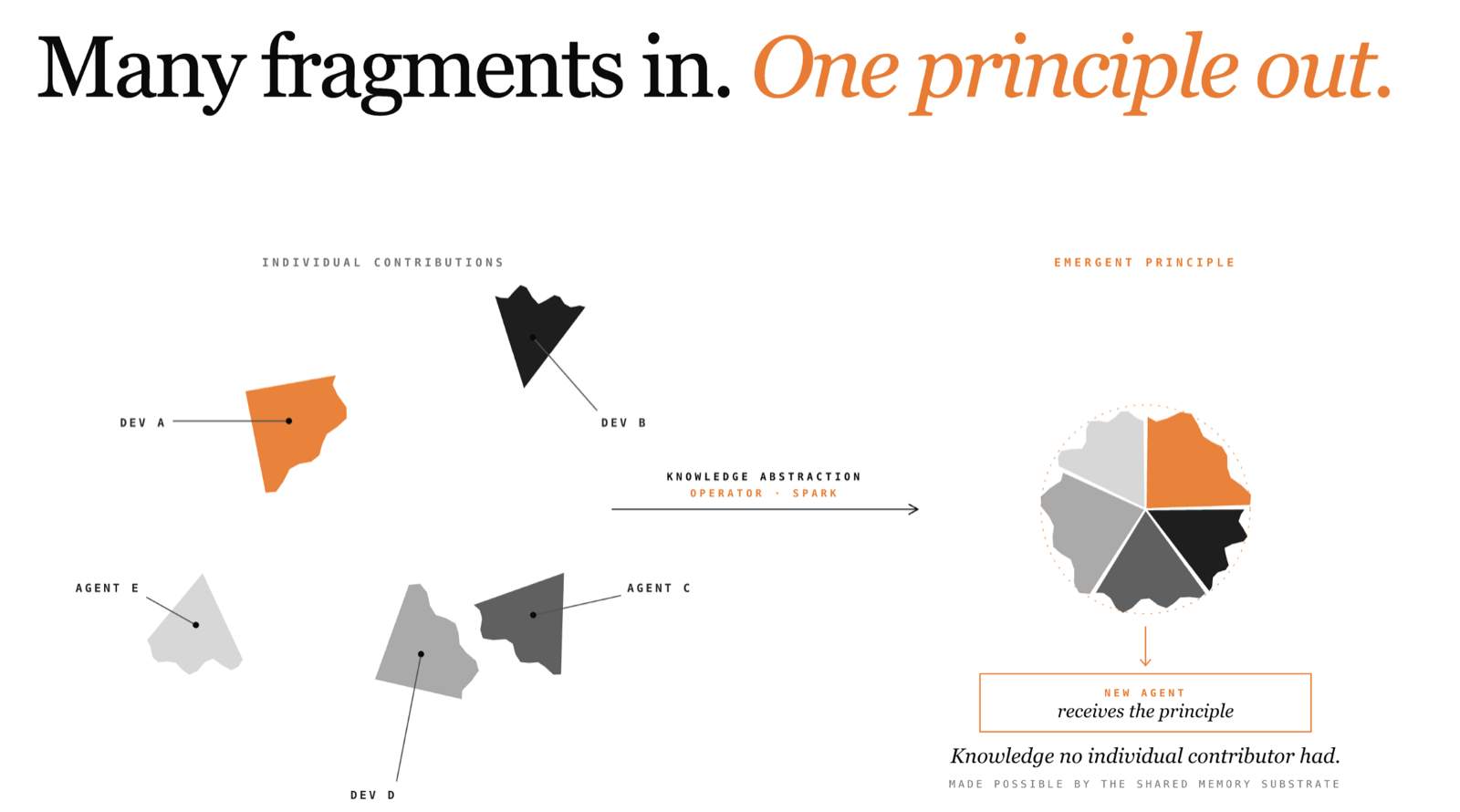
This is what Spark's Knowledge Abstraction operator does. When the memory accumulates enough specific insights that cluster around the same underlying principle, the operator detects the cluster and synthesises the general principle. In this case, after Alice's and Bob's insights arrive, the operator recognises that both address the same failure pattern across different PaymentService endpoints and produces a new piece of knowledge: PaymentService enforces undocumented input constraints and fails silently. Validate all inputs against known constraints, and verify state changes after every call.
This synthesised principle becomes a first-class piece of knowledge in the memory: retrievable, trust-scored, with full lineage back to its source insights. It was never contributed by any agent or user. It is emergent, the system recognised a pattern that was implicit across independent contributions and made it explicit.
What Happens Next
Carol starts building a subscription integration against the same API. She has never worked with the PaymentService before. Her agent queries Spark during planning and receives the abstracted principle. It doesn't only get Alice's specific fix about currency codes or Bob's finding about description lengths. It also gets the general principle that tells it what kind of API it is dealing with.
Carol's agent builds the integration defensively from the start. It validates inputs against every constraint it can identify. It verifies state changes after every call. It makes no assumptions about what the API will accept. The result: no silent failures, no debugging cycle, no frantic investigation in staging. Carol's integration works on the first deployment.
The difference in Carol's experience is worth examining. Alice spent hours debugging a silent failure she couldn't diagnose from the API's behaviour. Bob spent less time because he had Alice's insight, but still hit a second undocumented constraint. Carol hit none. Her agent understood the class of problem before encountering any specific instance of it.
The Ripple Effect
The value extends beyond the individual engineer. Without the abstracted principle, the team is playing whack-a-mole: each new engineer hits a different undocumented constraint, files a different bug, triggers a different staging failure. The constraints that get caught in staging are the lucky ones. Some will slip through to production. The legacy service silently dropping requests in production means failed transactions for real users, pages for the on-call DevOps team, and an incident post-mortem that recommends "better documentation". That documentation never gets written because the people who knew the system are gone.
With the principle in place, the entire class of problem is addressed before code reaches staging. Fewer staging failures mean faster release cycles. Fewer production incidents mean fewer pages for the on-call team and fewer users affected by silent request drops. The benefit compounds across engineering, operations, and the end users who never experience the outage that didn't happen.
This is where the economics shift. A static memory scales linearly: more fixes stored, more fixes retrieved. A memory capable of abstraction scales differently. After a few specific examples, it derives principles that help agents avoid whole classes of problems, including problems that nobody has encountered yet, in contexts that none of the original contributors worked in. That means better-designed integrations from the start, less engineer time wasted on preventable failures, and fewer tokens spent on trial-and-error debugging.
Why This Requires Shared Memory
Knowledge Abstraction works because Spark sees the contributions of the entire team. Alice and Bob did not coordinate. They did not know about each other's work. They did not even work on the same endpoint. The system recognised the pattern across their independent contributions and extracted a principle that neither of them explicitly stated.
A single-user memory cannot do this. One engineer working alone accumulates experience, but the evidence base is narrow, limited to the specific problems they have personally encountered. Abstraction requires diverse evidence: multiple independent observations of the same underlying pattern, from different contributors, in different contexts. The multi-user setting is what makes the evidence base rich enough for meaningful generalisation.
Trust scoring matters here too. The abstraction operator does not blindly merge everything in the neighbourhood. It weighs the evidence. Insights with higher trust, those that have been validated by feedback from multiple agents, contribute more to the synthesised principle. A grounding validation step checks that the claimed source insights actually support the generalisation. The system avoids producing plausible-sounding principles that aren't actually supported by the evidence.
The architecture: shared memory, trust-weighted evidence, autonomous operators, is a prerequisite. Knowledge Abstraction leverages that to create knowledge that did not previously exist.
§
Every team accumulates knowledge. The question is what happens to it. In most setups today, knowledge enters the system one piece at a time and stays exactly as it was entered. An engineer discovers a fix, records it, and some day another engineer might find it. The system faithfully returns what was stored.
That is useful. It is where Spark started, and it remains the foundation of what it does. But the interesting question is what happens after the knowledge accumulates. Does the system just store what your team already knows? Or does it learn things your team hasn't figured out yet?
We think the answer to that question is what separates a tool from infrastructure.
Get Spark for your team at www.memco.ai/spark/teams.