
Most conversations about AI agent ROI focus on success: how often does the agent get it right, how quickly, how cheaply. These are the right questions to ask. But they are not the only ones.
We recently ran a controlled experiment measuring the business impact of Spark, our shared agentic memory layer, on a set of real-world bug-fixing tasks drawn from SWE-bench. The headline results were exactly what we hoped to see: 40% lower costs, 34% faster execution in 31% fewer steps. We have written those up in full in our ROI white paper, which you can read here.
But the result I keep coming back to is a different one.
The Task That Never Got Solved
One of the ten tasks in our experiment — a bug from the scikit-learn repository — was never solved. Not in the baseline condition, and not with Spark either. The problem sits above the current capability ceiling of the model we used (Claude Sonnet 4.5). Without a human stepping in, it remains unsolved.
Here is what did change: with Spark, the agent used 15% fewer steps and cost 34% less, even though the outcome was identical. The agent still failed. It just failed faster, explored fewer dead ends, and produced a shorter, more focused trace for the developer to review before taking over.
I find this result more interesting than the efficiency gains on tasks that were already being solved. In production, not every task your agents attempt will be within reach of the current model. Every engineering leader knows this. The question most people have not been asking is: what does failure cost, and can you reduce that cost?
The data says you can.
The Same Mechanism, Every Time
What is striking about the full picture is the consistency. Spark reduces cost across every outcome category:
- On the three tasks the agent solved 100% of the time, cost fell by 34% and steps by 24% — with no change in pass rate. The agent did not get smarter; it got more efficient.
- On the variable-outcome tasks (which are sometimes solved, and sometimes not), Spark improved the pass rate and produced a clear transition point after which the task was solved reliably in subsequent runs. Baseline agents never reached that kind of stability.
- On the task that was never solved, the cost of the failed attempt also fell by 34%.
Try Spark
Give your agents memory in 30 seconds.
Plugs into Cursor, Claude Code, Copilot, and Windsurf via MCP. Free for individual developers. Your code never leaves your machine.
npm install -g @memco/spark
Rolling out AI at your company? Talk to us about a pilot
The mechanism is the same in each case. The shared memory gives the agent a shorter path through the problem space, whether that path leads to a solution or to a faster recognition that the problem is beyond reach. As the "capability ceiling" of foundation models rises, the value of Spark shifts from finding a path to optimizing the path, as evidenced by the 35% cost reduction on "easy" tasks.
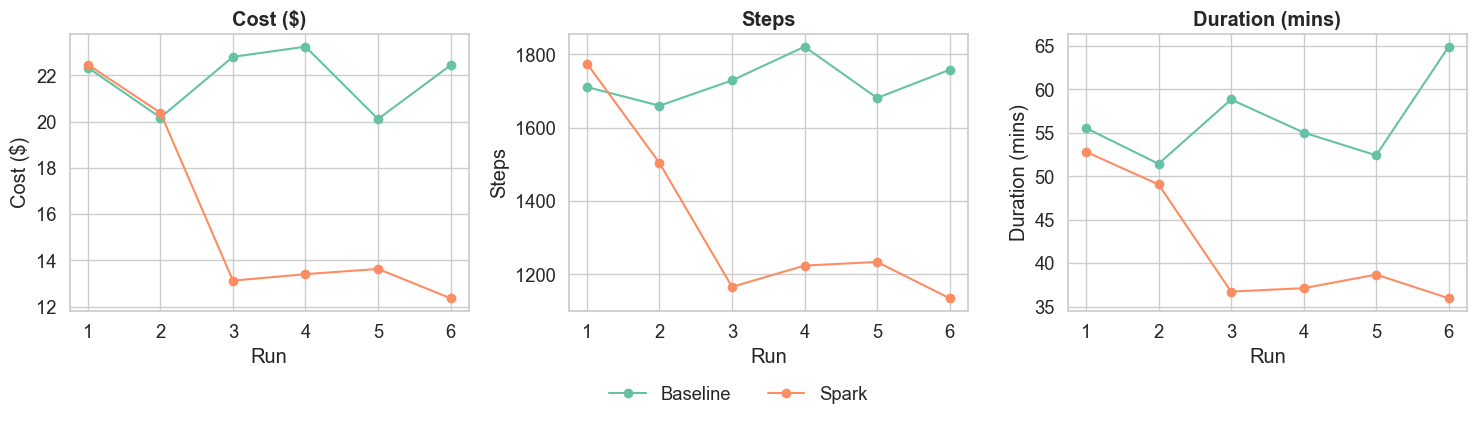
This figure (borrowed from the paper) tells the story: as you keep exploring the same space, Spark reduces resource use:
Is This a Small Sample?
That is a fair question, and I want to address it directly.
The experiment covers 10 tasks run 12 times each (6 baseline, 6 Spark). That is not a large dataset. But the regression analysis we ran finds a statistically significant association between the quality of knowledge retrieved from Spark and reductions in cost, duration, and steps — at p < 0.001. Each relevant piece of knowledge retrieved is independently associated with $0.34 in cost savings and 23 fewer agent steps.
Small datasets make it harder to reach statistical significance, not easier. The fact that the signal is this strong in a small experiment is an indication of how robust the underlying effect is. We are continuing to run further experiments across a broader range of tasks and models, and we will publish as we go. But we did not want to wait for a larger dataset before sharing these results.
What This Means in Practice
For a 10-developer team, the projections from steady-state adoption are: over $80,000 in direct LLM cost savings per year, and approximately 257 hours of developer capacity freed per month — time that can go toward the work that agents are not yet capable of.
The adoption curve is short. Run 1 seeds the shared memory at no additional cost, simply by having agents do their normal work. By run 3, the full efficiency benefit has arrived and costs have stabilised at 40% below baseline.
Perhaps most importantly for teams trying to scale their AI adoption: cost variance more than halved. The standard deviation in cost per run dropped from $1.36 to $0.55. Sprints become forecastable, and budgets become manageable. That predictability is a prerequisite for scaling agent use across an engineering organisation, and it is something that raw model capability improvements alone cannot give you.
The Broader Point
We tend to evaluate AI agents on a binary: did it succeed or not? This data points at a different framing, one that's important when thinking about production systems at scale.
The full cost of running agents includes the cost of the tasks they succeed at, the cost of the tasks they are still learning to succeed at, and the cost of the tasks they will not succeed at for some time yet. Shared memory reduces all three. The agents work more efficiently when they succeed, and they fail more cheaply when they do not.
That is the economic case for Spark. You can read the full white paper, including the regression analysis, at this link. As always, I am interested in your reactions. particularly if you have run similar experiments or have questions about the methodology.